Visual Question Generation
Motivation
In this article, I am proposing an algorithm for creating a series of questions about a natural image. There has been a recent interest in problems in multi-modal AI and specifically in the combination of Computer Vision with NLP. There have been multiple datasets (VQA and Visual Madlibs) that attempt to have a series of question and answer pairs for an image. Instead of curating question answer pairs, if we could generate a large number of questions about images, I contend that our algorithms would stand a better chance of solving multi-modal AI problems like commonsense reasoning and question answering.
Introduction
There are a string of successes in using deep learning for object recognition and image captioning among other tasks. However the state of the art in answering open ended questions lies around 60% (for the VQA dataset). I propose that by greatly increasing the number of questions about each image, and by having the ability to ask questions about other images we will see the number of correct answers jump by a large factor.
However, the sapce for asking questions is much larger than the space of answers. The number of questions that one can ask about a scene is nearly infinite and varied. For any given question on the other hand there are a few plausible answers. For this reason I developed a system, where for any given image you can generate a question and manipulate the first word of the input to generate more questions.
Related Work
There is not any directly applicable work in the not been attempts to learn the question space from images, there have been attempts at creating a series of questions about bodies of text.
In Computer-Aided Generation of Multiple-Choice Tests[3], the authors picked the key nouns in the paragraph and and then use a regular expression to generate the question. In Arikiturri [4], they use a corpus of words and then choose the most relevant words in a given passage to ask questions from. These questions are again designed to fit a specific regular structure. Few attempts have been made in recent years, and most of them rely on fixed patterns for the questions.
In the image domain, there have been attempts at visual question generation and image understanding. To do this there have been multiple datasets created, though they're overall size is small when comparing to datasets like MSCOCO and ImageNet Visual Madlibs[6]: In Visual madlibs people generate fill in the blank question answer pairs which can be used in deep learning models to understand more about the images in them. VQA[1] is another dataset that has a series of non-trivial questions about the images which are sourced both from MS COCO and from a custom abstract scene creation tool. They also contain Mulitiple Choice along with Open Ended question The Visual Genome project by Fei Fei Li et al, takes dense descriptions from a series of images and tries to build relations between all the objectd in the scene. Lastly we have Visual 7w[7] which attempts to split questions into 7 types based on the starting words in the question and choose local images in the scene to ask answer particular questions.
Through the rest of this article, we will focus on the VQA dataset and use it as a baseline model on which to build our system.
Algorithm
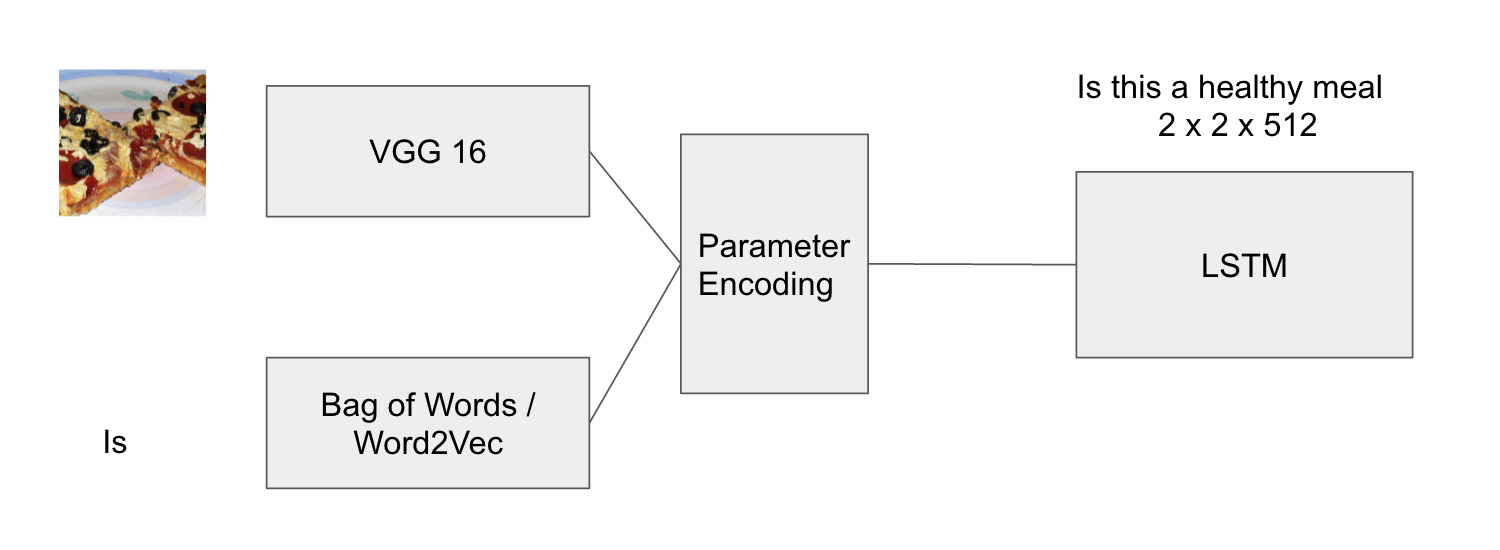
There are three methods that we are going to discuss. The first is a baseline test of passing a series of Convolution based features to an LSTM and training it to output a bag of words which forms the sentence. The second method uses the a combination of image features and a 1-of-k representation of the first word input to the LSTM which then generates the output. The second uses a 1 * 1 *1024 dimension Word2Vec output which is then multiplied with the CNN features to create an input to the LSTM.
We used a Bidirectional LSTM to model our language 2 * 2 * 512. The output of the LSTM is always a bag of words feature that the user means to ask. The final layer of the LSTM is equal to the longest sentence in the input. A special start and stop symbol is added to the input bag of words. The Convolutional Features are selected by trying to align with the words in the question to develop a model as to when to ask which question. We are trying to align the words in the questions to the output of the images similar to the method in Deep Visual Alignments, Karpathy et. al [2]
We are using the VQA dataset as a database to train our models. The network was trained on the Real images section of VQA and under the Open Ended set of questions. We have 3 training questions for each image in the dataset
Network Description
I used the VGG-net 16 as a CNN to generate the image features. The features are connected from the last fully connected layer. This is 4096 dimensional feature vector which is fused with the Word2Vec input using element-wise multiplication, similar to that seen in the VQA dataset. With the bag of words encoding, the input is transformed into a 1024 vector with one fully connected layer which is then input into the LSTM
I used stochastic gradient descent to backpropogate in the Convolutional network and RMS Prop in the RNN. The size of the final dataset used was 50,000 images, each with 3 captions for each question. The training was run for 100 epochs and the training error was calculated at every 1000 iterations. The images were split into batches of 16 for minimizing training time.
Error was calculated as the deviation of each word from the output that we are training on.
The work was done in Torch and can be found here
Results

The results were mixed with all images generating questions, but the variation in the questions not being large. Over 60% of the questions generated are in the form "What is the man _____", which overall while being a valid question lacks the depth to create a database from.
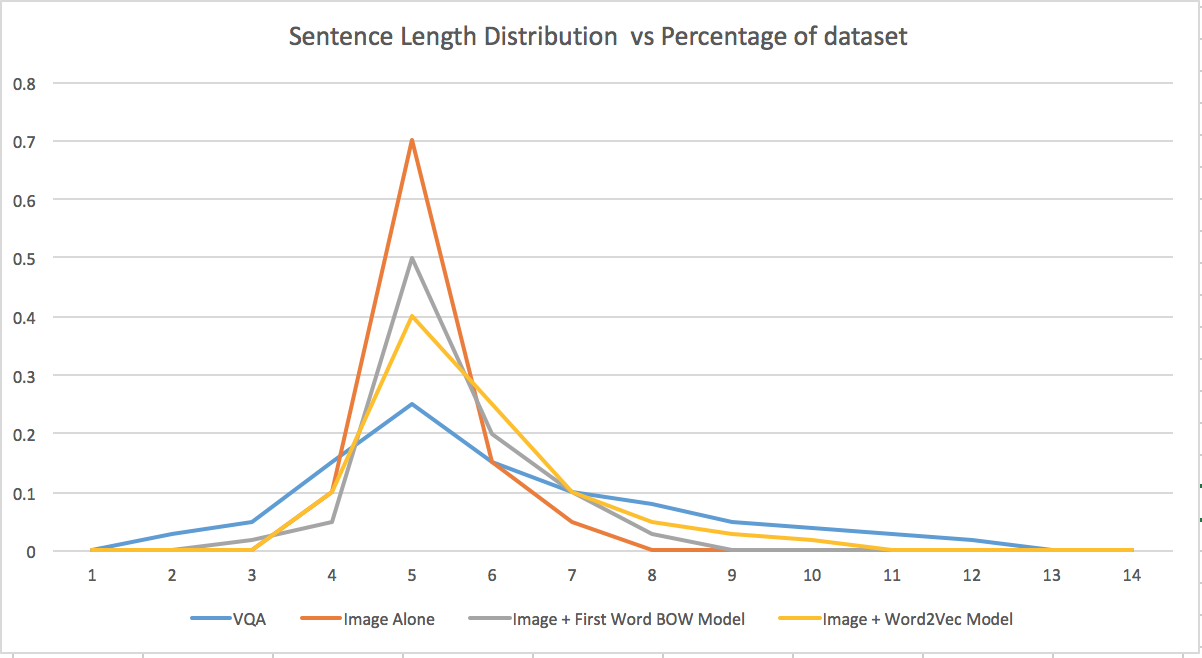
This is the spread of the number of words in each of the three methods compared with the original dataset is here. We are trying to model the distribution of sentence lengths in blue. As can be seen there is a marked difference between the Word2Vec model vs the image alone, which is suggestive that Word2Vec might be more accurate.
I, then took 50 questions from each of the 4 sets and rated whether the question was indeed plausible for the images.The results are shown below. (Question represents the original dataset, which at 49 is always plausible)
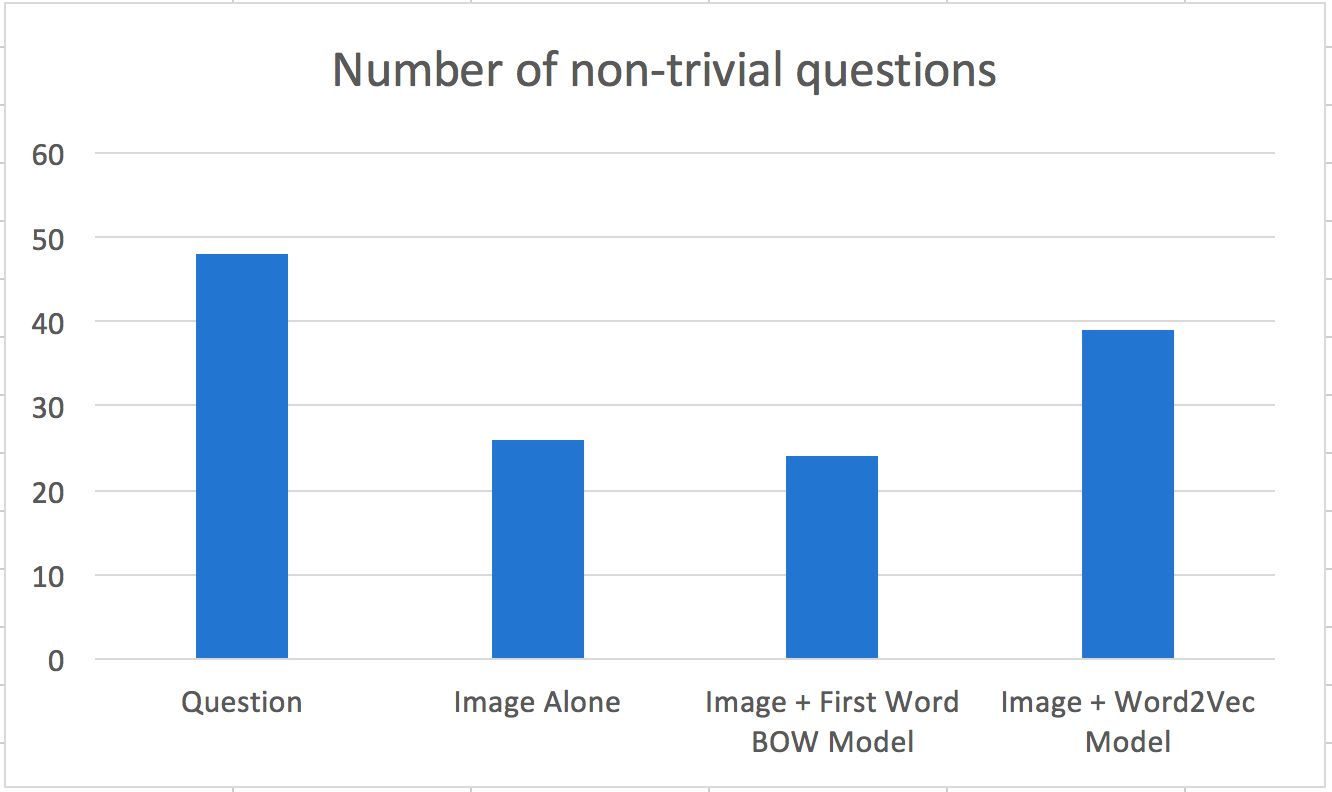
Again, the Word2Vec method beat out the competition to acheive a much higher score than all others suggesting that this feature encoding holds promise for more work in the future
Conclusions
The bag-of-words method clearly performs the best of all the methods, however to ask questions due to their very nature new methods will have to be developed. This is insufficient to capture the space of questions that one can truly ask. Future work may go into how to use the bag of words to cause enough jitter to still ask sensible questions and artifically increase size that way
References
[1]Antol, Stanislaw, et al. "VQA: Visual question answering." Proceedings of the IEEE International Conference on Computer Vision. 2015.
[2]Karpathy, Andrej, and Li Fei-Fei. "Deep visual-semantic alignments for generating image descriptions." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
[3]Mitkov, R., & Ha, L. A. (2003, May). Computer-aided generation of multiple-choice tests. In Proceedings of the HLT-NAACL 03 workshop on Building educational applications using natural language processing-Volume 2 (pp. 17-22). Association for Computational Linguistics.
[4]Aldabe, Itziar, et al. "Arikiturri: an automatic question generator based on corpora and nlp techniques." Intelligent Tutoring Systems. Springer Berlin Heidelberg, 2006.
[5]Li Fei-Fei, et al. "Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations"
[6]Alexander Berg, Tamara L. Berg, et al. "Visual Madlibs: Fill in the blank Image Generation and Question Answering" arXiv preprint 2015
[7]Zhu, Yuke, et al. "Visual7W: Grounded Question Answering in Images." arXiv preprint arXiv:1511.03416 (2015)
02 May 2016